I am trying to reproduce the second step (run the classifier in the cropped objects) of the AddaxAI platform by myself in Python because I want to access some final layers of the model to test some OOD/anomaly detection methods. However, I’m not being able to get the same results.
First, I selected a subset of 80 images and have passed them into the AddaxAI entire workflow with Megadetector 5a and Southwest USA model.
Then, I exported the cropped objects from the Megadetector 5a and tried to implement the SouthwestUSA model by myself in Python (downloaded here)
Most of the predicted classes are the same, but the confidence scores are often quite different. I am reshaping the cropped images to 299x299 as recommended.
One difference I realized that it is related to the “unidentified animal” class because the classification score is below the classification threshold, and thus the exported result shows the detection score rather than the classification score.
However, for many images the classification score is quite different and for a few images the predicted class is different. For example:
Is the “sdzwa_southwest_v3.pt” file, that is provided in the link, correct? Is it different from the model used in AddaxAI?
Or I’m missing a preprocessing step in the classification pipeline?
I would greatly appreciate any insights/thoughts on this.
Thanks!!
It is very hard to tell you what is going on without knowing your code, but
I can help you to understand what happens in AddaxAI under the hood. See below some information that might help debugging.
Thank you very much for your quick and detailed response! That helps a lot!
I implemented the model following the code in GitHub that you shared (see below).
However, I am still getting the same results that are different in comparison to when I run it directly on AddaxAI.
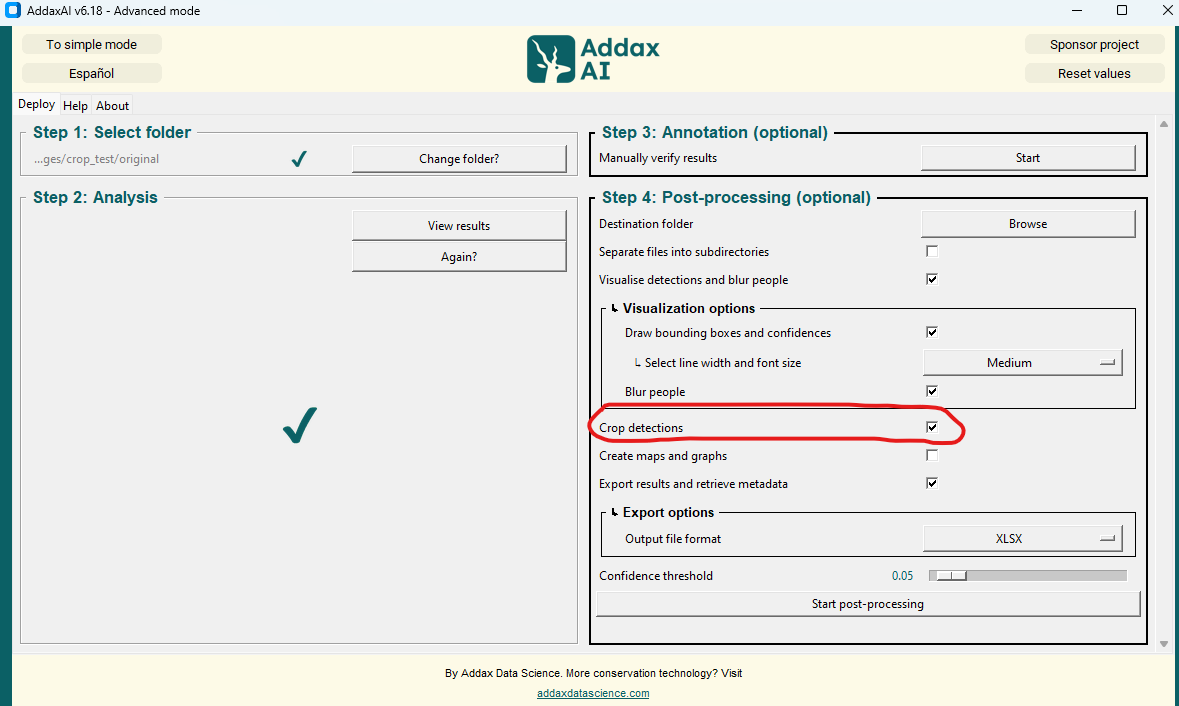
I’m suspecting that this difference could be related to the cropping procedure. I’m running the MegaDetector 5a in AddaxAI and cropping the animal objects by selecting the option “Crop detections” in the “Step 4: Post-processing”:
Thanks Peter! I will try to implement the 2 steps in Python then, to see if I can get the same results.
We are exploring some out-of-distribution detection approaches to detect, for example, species for which the model was not training (e.g., armadillos here in Florida).
For some of these methods, we need the extracted features from the dense layer right before the classifier part. Then, I was trying to export these vectors of features to test these OOD detection methods.
Regarding the SouthwestUSAv3 model, one thing that I noticed is that there is a “other” class, but I could not find more information about. Do you know if this model was trained specifically including this class or if there is a different procedure to define “other” species?
Yes, the “other” class is baked in, which means the developers have indeed grouped some animals together into a “other” class. I do not know which animals that were.
I’m still a bit lost trying to implement the Southwest USA v3 model.
In the folder (Addax-Data-Science/SWUSA-SDZWA-v3 at main), I see two files that could correspond to the model architecture and/or weights:
That is indeed a bit confusing. Let me explain the two files and what they do.
southwest_v3.pt = the trained weights
efficientnet_v2_m-dc08266a.pth = the underlying model architecture and its pretrained checkpoint
To run inference, we need both. The reason you couldn’t find the southwest_v3.pt part in the code, is that it is hidden as the variable cls_model_fpath. See lines 17 and 105 in the inference script
We need to load both files, which happens on lines 43 and 105.